The explosion of data-driven decision making is motivating businesses to have a data strategy to provide better customer experiences, improve operational efficiencies, and make real-time decisions based on data. As businesses become data driven, we see more customers build data lakes on Azure. We also hear that more cost optimization and more performance are two of the most important features of data lake architecture on Azure. Normally, these two qualities are traded off for each other—if you want more performance, you will need to pay more; if you want to save money, expect your performance curve to go down.
That’s why today, we’re announcing the preview of Query Acceleration for Azure Data Lake Storage—a new capability of Azure Data Lake Storage, which improves both performance and cost. The feature is now available for customers to start realizing these benefits and improving their data lake deployment on Azure.
How Query Acceleration for Azure Data Lake improves performance and cost
Big data analytics frameworks, such as Spark, Hive, and large-scale data processing applications, work by reading all of the data using a horizontally-scalable distributed computing platform with techniques such as MapReduce. However, a given query or transformation generally does not require all of the data to achieve its goal. Therefore, applications typically incur the costs of reading, transferring over the network, parsing into memory and finally filtering out the majority of the data that is not required. Given the scale of such data lake deployments, these costs become a major factor that impacts the design and how ambitious you can be. Improving cost and performance at the same time enhances how much valuable insight you can extract from your data.
Query Acceleration for Azure Data Lake Storage allows applications and frameworks to push-down predicates and column projections, so they may be applied at the time data is first read, meaning that all downstream data handling is saved from the cost of filtering and processing unrequired data.
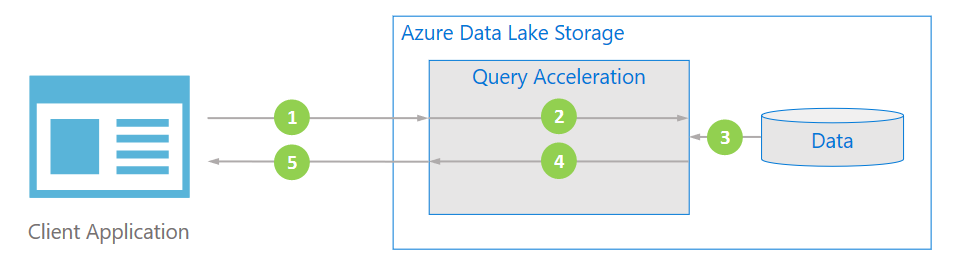
The following diagram illustrates how a typical application uses Query Acceleration to process data:

- The client application requests file data by specifying predicates and column projections.
- Query Acceleration parses the specified query and distributes work to parse and filter data.
- Processors read the data from the disk, parses the data by using the appropriate format, and then filters data by applying the specified predicates and column projections.
- Query Acceleration combines the response shards to stream back to client application.
- The client application receives and parses the streamed response. The application doesn't need to filter any additional data and can apply the desired calculation or transformation directly.
Azure offers powerful analytic services
Query Acceleration for Azure Data Lake Storage is yet another example of how we’re committed to making Azure the best place for organizations to unlock transformational insights from all data. Customers can benefit from tight integration with other Azure Services for building powerful cloud scale end-to-end analytics solutions. These solutions support modern data warehousing, advanced analytics, and real-time analytics easily and more economically.
We’re also committed to remaining an open platform where the best-in-breed open source solutions benefit equally from the innovations occurring at all points within the platform. With Azure Data Lake Storage underpinning an entire ecosystem of powerful analytics services, customers can extract transformational insights from all data assets.
Learn more
To find out more about Query Acceleration for Azure Data Lake Storage you can:
- Sign up for the Azure Data Lake Storage preview program.
- Read the Azure Data Lake Storage documentation.
- Learn how to use Query Acceleration for Java and .NET.
- Understand the pricing model for Query Acceleration.
- Learn more about Azure Data Lake Storage.